


 Кейсы
Кейсы



Комплексное
продвижение
вашего
сайта


О том, что SEO умерло, говорят уже лет десять. Это, конечно, неправда. Просто алгоритмы поисковых систем научились лучше понимать интент пользователя и анализировать сайты. Теперь не получится выйти в топ с текстом о шторах, в котором вставлены запросы «купить квартира Москва цена недорого». А раньше так писали. Важны были именно точные ключевые фразы, чем больше, тем лучше. Содержание текста и соответствие теме не имели значения, поэтому о SEO-текстах до сих пор говорят с пренебрежительным оттенком.
Поисковые системы, как любая коммерческая организация, ставят своей целью максимально удовлетворять запросы пользователей, поэтому алгоритмы улучшаются и приоритет постепенно смещается в сторону полезных для читателя текстов. LSI-копирайтинг как раз об этом – о написании экспертного контента, дающего подробный ответ на запрос пользователя. В этой статье расскажем об основных отличиях, чем он полезен для SEO и как правильно писать такие тексты.
LSI-копирайтинг – это создание текстов с использованием синонимов и тематических фраз, собранных на основе данных латентно-семантического индексирования. Латентно-семантический анализ запатентовали еще в 1998 году. Его суть заключается в выявлении ассоциативных и семантических связей путем сопоставления слов и документов. Именно этот метод «понимания» содержания используют в своих алгоритмах Google (2011 г. «Панда», 2013 г. «Колибри») и «Яндекс» (2016 г. «Палех», 2017 г. «Королев»).
Конечно, система не понимает смысла текста. Она просто анализирует документы, удовлетворившие запросы пользователя и одобренные асессорами, смотрит, какие слова совпадают, и считает, что именно они связаны с темой и помогают раскрыть вопрос полностью.
Для простоты понимания приведем пример.
Если вы введете в поисковую строку слово «докторская», поисковик не поймет, что именно вы хотите – колбасу, диссертацию, степень или что-то еще, поэтому уже в строке поиска вам предложат поисковые подсказки.
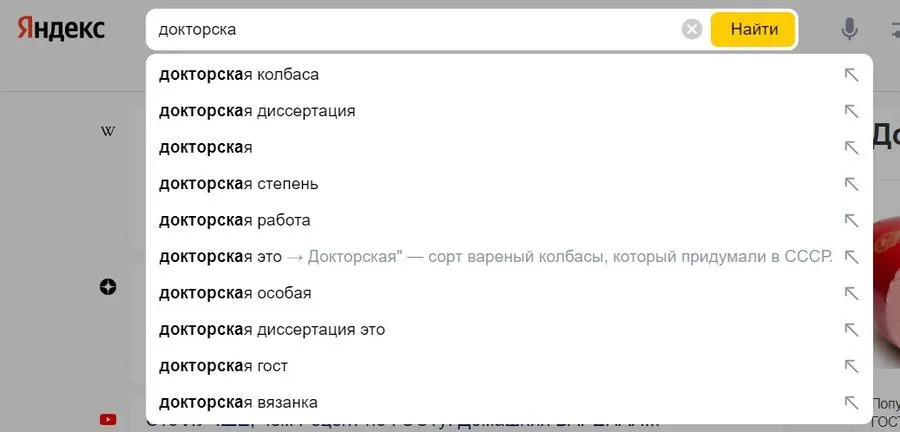
Стоит добавить уточнение, и поисковые подсказки изменятся. Здесь уже не будет никаких диссертаций и колбас.

Если вы запустите поиск, выдача будет релевантна вашему запросу. Система сразу отсечет все документы другой тематики и на основе опыта «поймет», что вы хотели узнать об обучении. Поэтому выдача будет о докторантуре, хотя вы и не использовали это слово в запросе. Более того, точного вхождения и даже разбавленного вы не найдете в тайтлах и сниппетах. Выдача построена на ассоциациях.

Если вы введете запрос «колеса на Логан», обученная поисковая система поймет, что вы хотите, и добавит в выдачу страницы, у которых в тайтле и сниппете нет этого слова, но есть синонимичные: шины, покрышки.
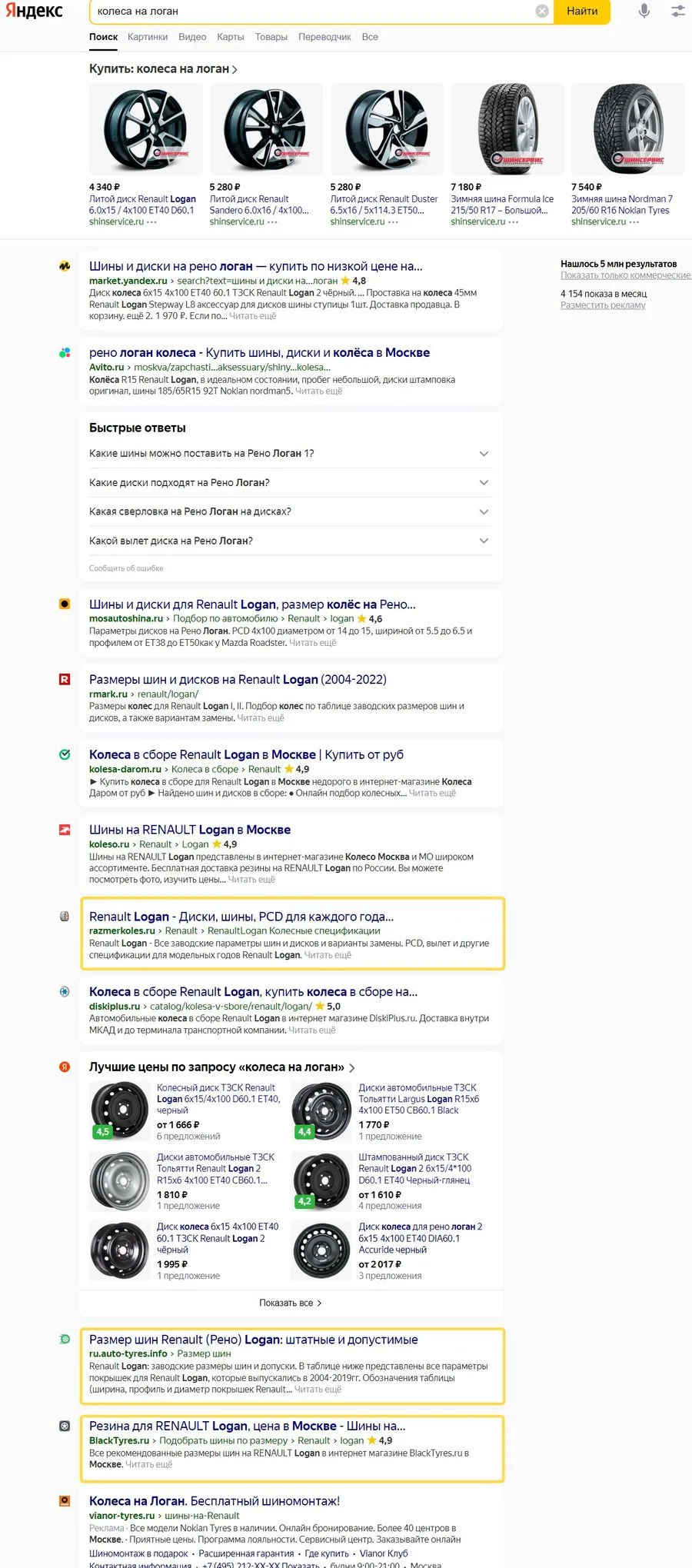
На скриншоте выше у трех сайтов из десяти в органической поисковой выдаче нет вхождения вашего запроса, а «Логан» практически везде написан латиницей. Выдача построена на синонимах.
Именно так и выглядят результаты использования LSI: в тексте не обязательно должно быть точное вхождение и даже сам ключ, достаточно комплекса ассоциированно связанных слов и синонимов. На практике, конечно, все чуть сложнее, об этом расскажем дальше.
В тексте, написанном с использованием скрытого семантического индексирования, должны быть два типа слов:
Для подбора этих слов автор может вручную проанализировать топ, посмотреть форумы, но это долгий и трудозатратный способ. Более эффективно пользоваться подсказками и сервисами поисковиков, сторонними программами.
Мы уже показали выше, что при вводе запроса в строку поиска система предлагает варианты для конкретизации. Эти фразы вы можете добавить в текст, конечно, если они помогут раскрыть тему и будут уместны.

По запросу «декоративная штукатурка» появились дополнительные фразы «шелк», «короед», «фактура», «виды», «бежевая», «серая», «для стен», «своими руками». Если вы описываете виды декоративной штукатурки, все эти слова можно использовать в тексте.
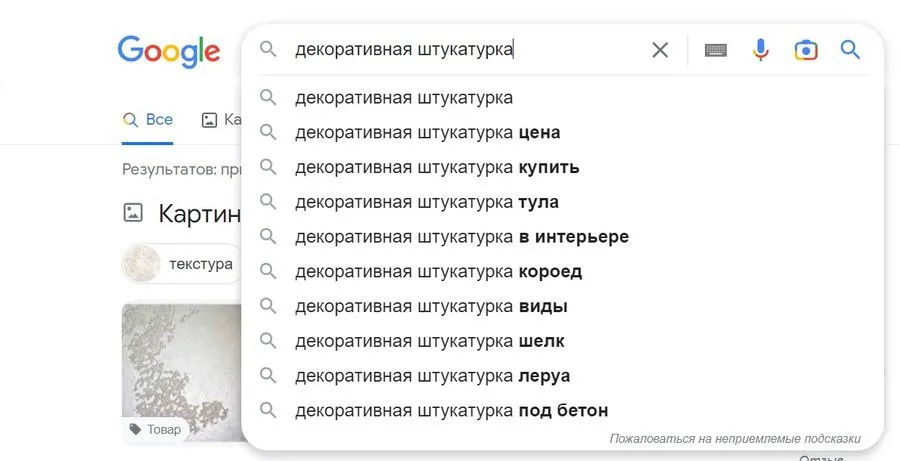
В «Гугле» подсказки немного отличаются, в нашем примере добавились коммерческие фразы.
Кроме поисковых подсказок, вы можете использовать рекомендации под строкой поиска.

Рекомендации из строки поиска и под ней не совпадают. По сути, это другое представление блока «Люди ищут», который всегда размещается в самом низу страницы под последним результатом выдачи.
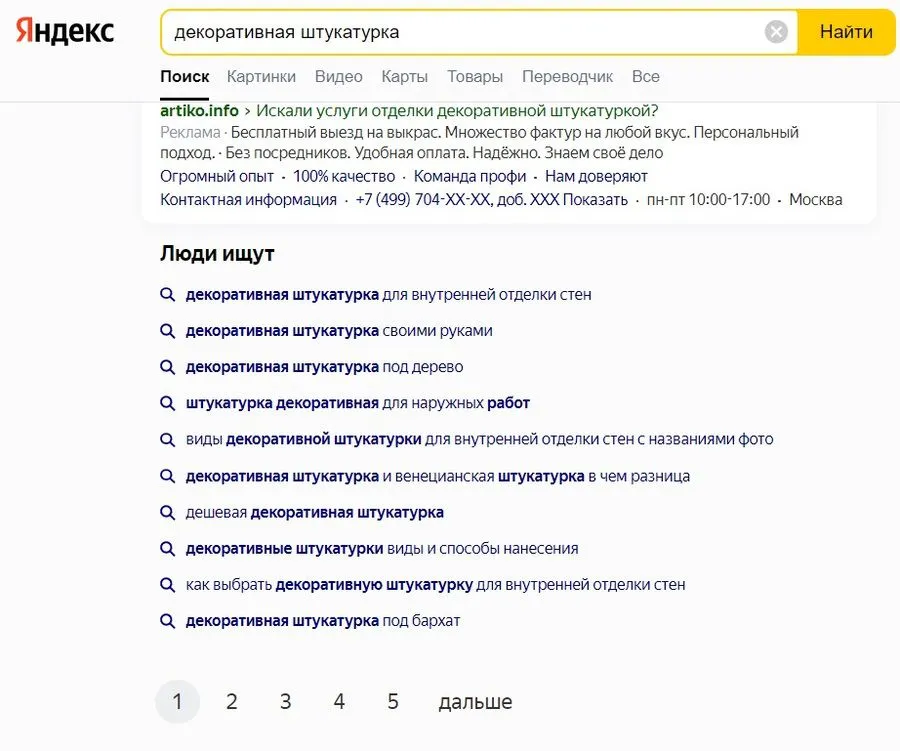
Это бесплатный сервис по подбору слов от «Яндекса». На сбор списка для LSI-текста потребуется почти столько же времени, как при использовании предыдущего метода.

Здесь список запросов больше, повторяются фразы, которые мы уже видели на странице поисковой выдачи.
Аналог «Вордстата» в Google – «Планировщик ключевых слов» Google Ads.
В отличие от предыдущих вариантов можно сразу загружать все ключевые фразы, а не собирать семантику поштучно. Для сбора LSI-слов есть платные и бесплатные инструменты, ниже перечислим три самых популярных.
«Парсинг подсветок» Арсенкина. Работает бесплатно, ограничение касается только количества выгрузок. Собираются данные из подсветок (синонимичные) и слова, задающие тематику (релевантные). У этого сервиса есть еще один удобный инструмент – парсинг заголовков. Его тоже стоит использовать при разработке LSI-текстов, так как он собирает данные о заголовках и подзаголовках, которые есть у ваших конкурентов в поисковой выдаче, это поможет лучше раскрыть тему.
Инструменты «Пиксель Тулс». Работает платно, но есть пробная бесплатная 30-дневная подписка за рубль, также получить бесплатный доступ можно, если пригласить рефералов и выполнить другие условия. В сервисе много интересных инструментов, включая парсинг подсказок «Яндекса» и Google, результаты из блока «Люди ищут» и возможность создания полноценного технического задания для копирайтера.
«Акварель-генератор» от Just Magic. Инструмент платный и достаточно дорогой, но идеально подходит тем, кто не хочет тратить время и постоянно работает с LSI. Анализирует не только выдачу, но и сами страницы, собирая список слов.
Если брать усредненные тексты и усредненные требования, то SEO – это больше про цифры, которым должен соответствовать контент, чтобы понравиться поисковой системе: соблюдение плотности слов, технические требования к уникальности, количество точных вхождений, общее количество слов, обязательное использование запроса в первом абзаце и прочее. LSI-копирайтинг – это больше про удобство для пользователя, поэтому здесь на первое место выходит экспертность контента, простота подачи информации (текст уступает инфографике и таблицам), если задача ставится копирайтеру, то добавляется еще список синонимичных и ассоциированных слов.
| отличия | SEO-тексты | LSI-тексты |
|---|---|---|
| Цель | Написать текст, соответствующий требованиям ПС, вставить конкретное количество слов в определенном порядке. | Написать текст, который удовлетворит запрос пользователя, полностью раскроет проблему. |
| Запросы | Нужно соблюдать количество и тип вхождения, обязательно размещать в заголовках и первом абзаце, а остальные распределять по тексту. | Нет требований. |
| Плотность слов | Не должна превышать 4% по слову. | Нет требований, но процент LSI-слов должен быть больше остальных. |
| Оформление | Не прописывается в техническом задании. | Обязательно использование иллюстраций (фото, таблицы, видео, инфографика и т. п.). |
| Структура | Должны быть заголовки и подзаголовки с ключами. | Приоритет многоуровневой иерархии заголовков с подзаголовками для четкого понимания структуры текста. |
| Уникальность | Должна быть выше 90%. | Возможна низкая уникальность в специализированных тематиках. |
| Количество слов | 300–450 слов. | 700–1500 слов, может быть больше, если это нужно для раскрытия темы. |
Специалисты по продвижению сайта давно стали объединять LSI и SEO. В ТЗ, кроме запросов, добавляются списки тематических слов, увеличивается объем текста (или указывается, что его можно неограниченно расширять при необходимости раскрытия темы) и добавляются пожелания о подборе иллюстрирующих изображений и видео. Такие тексты работают сразу на две цели: соответствие требованиям поисковых систем и запросу пользователя. Свобода в отношении SEO-фраз и уникальности зависит от конкретной тематики, полный отказ от ключей возможен только по определенным запросам. Чем так хороши LSI-тексты для SEO?
Поисковая система только пытается понять текст, но не понимает его на самом деле, поэтому в выдачу все еще могут попасть бессвязные страницы, просто содержащие список нужных слов. Также поисковый робот не разбирается в многозначных словах, поэтому если в тексте о замках вы используете слово «запор» в значении медицинского термина, робот не заметит проблемы.
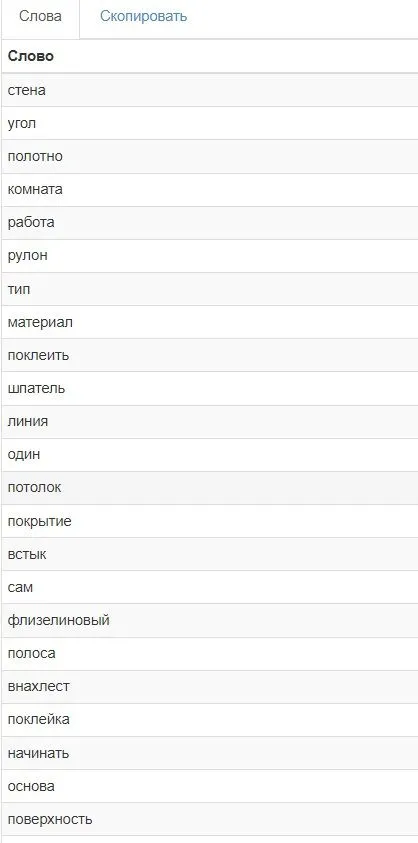
Добавим, что писать LSI-тексты дольше и дороже. Копирайтеру придется сначала собрать список релевантных и синонимичных слов, чтобы на их основе составить структуру и подобрать качественную информацию. Эксперт этот этап пропускает, так как экспертный текст автоматически содержит LSI-слова. Приведем простой пример: вы не сможете дать инструкцию по оклеиванию обоями без слов «стена», «рулон», «поверхность», «материал», «встык» и т. п. Именно эти слова рекомендует использовать инструмент Арсенкина (см. скриншот ниже).
Результат работы LSI-копирайтера можно оценить только со временем, так как просто наличие нужных слов не гарантирует положительный отклик у целевой аудитории. Качество текста можно оценить по таким метрикам, как процент отказов, количество запросов, по которым статья показывается в топе, длительность сессии пользователя, карта скроллинга, появление входящих ссылок и прочим.
LSI-копирайтинг позволяет писать хорошие качественные тексты для пользователя, не требуя от автора нарушать правила русского языка, высчитывать спамность и рерайтить названия законов ради уникальности. Постепенно к этому приходит и SEO-копирайтинг, в который уже внедряются элементы LSI. Польза от текстов, написанных с учетом метода скрытого семантического индексирования, для SEO-продвижения неоспорима: трафик больше за счет ранжирования по низкочастотным запросам, пользователи довольнее, что влечет за собой рост позиций сайта в целом и отсутствие необходимости переписывания контента при каждом обновлении алгоритмов. Хотите узнать больше о копирайтинге и SEO-продвижении? Читайте блог «Поисковой индустрии»! Рассказываем простым языком о сложном и делимся секретами успешного развития бизнеса с помощью инструментов интернет-маркетинга.
Материал проверен редакцией «Поисковая индустрия»
по поводу seo-продвижения, выхода в топ
или интересует другая информация,
напишите или позвоните нам по номеру:







Вместе с аудитом
мы даем структуру
конкурентов в поиске

по поводу seo-продвижения, выхода в топ
или интересует другая информация,
напишите или позвоните нам
по номеру:
Укажите ваш номер телефона и введите промокод
соответствующий интересующему вас спецпредложению

